Kapittel 10 Arbeid med filer
Så langt har programmene våre ikke kommunisert med omverdenen i særlig grad. Dette gjør de temmelig begrenset. En utrolig vanlig måte å kommunisere med omverdenen på er via filer. Når programmene dine kan lese fra og skrive til filer har de mye mer påvirkningskraft. Du kan lagre ting permanent slik at programmet kan ha en varig effekt på omverdenen. I dette kapittelet skal du lese fra og skrive til en drøss med forskjellige filtyper som tekstfiler, CSV-filer, JSON-filer, og binærfiler. Til slutt skal vi bruke det vi har lært til å analysere hyppigheten av bokstavbruk i den kjente romanen Frankenstein av Mary Wollstonecraft Shelley.
10.1 Introduksjon - Evaluering av planeter i fjerne galakser
Etter å ha nedfryst kroppen din i et kryokammer våkner du i år 5000. Selv om du er litt forvirret, har du fortsatt Python-kunnskapene dine i behold. Det er derfor enkelt å skaffe deg en jobb der du analyserer atmosfærene til planeter i jakten på flere beboelige planeter.
Det oppdages nye planeter hver dag i det store menneskelige imperiet. Planetene får rapportert følgende målinger i atmosfæren sin:
Mengden oksygen, nitrogen, og karbondioksid.
Temperatur på planetoverflaten.
Mengden elektromagnetisk stråling.
Informasjon om de nye planetene kommer inn som strukturerte tekstfiler hver dag. Målet er å bruke Python til å analysere om noen av planetene kan være beboelige for vår sivilisasjon. Etter en solid dose med hardt arbeid skriver du et knallbra program i Python for å analysere om en planet er beboelig basert på verdiene over.
Siden du ikke har lært å lese inn informasjon fra filer enda, blir du nødt til å kopiere informasjonen fra filene over i variabler i programmet manuelt. Det går greit i begynnelsen, men du blir fort lei av å gjøre dette hver dag. Siden du heller ikke kan skrive til filer blir du nødt til å kopiere konklusjonene til filer manuelt før du sender dette videre til dine overordnede. Ikke særlig morsomt arbeid!
Ved å lære å lese fra og skrive til filer vil analysene dine kunne kjøre uten at du trenger å klippe og lime informasjon fra og til programmet ditt. Da kan du heller bruke fritiden din på interplanetariske intriger.
Det er ikke bare i fantasihistorien over at skriving til filer er nyttig. Verden er full av programmer som både leser fra og skriver til filer. Dette er nyttig i alt fra fakturaer i finansverdenen til dataanalyse av brukermønstre på en nettside. I dette kapittelet skal du lære det mest sentrale om å lese fra og skrive til filer i Python.
10.2 Lese fra og skrive til en tekstfil
Tekstfiler kan inneholde alt fra trafikkdata fra passeringer på E6 til litterære verk. Det er mange situasjoner der vi ønsker å analysere eller endre innholdet i en tekstfil. Her skal vi først se på den enkleste måten å lese fra og skrive til tekstfiler med den innebygde funksjonen open(). I neste seksjon skal vi ta for oss konteksthåndterere, som er en tryggere måte å jobbe med tekstfiler i Python.
10.2.1 Lese fra filer
Lag deg en mappe der du oppretter to filer:
En Python-fil som heter
arbeid_med_filer.py.En tekstfil som heter
dikt.txt.
I filen dikt.txt kan du lime inn det vakre diktet Være sammen av Arne Ruset:
Vi kan ikkje eige kvarandre
tusen dikt har fortalt oss
at vi ikkje kan eige kvarandre
men vi kan låne kvarandre
og gløyme levere tilbakeVi skal nå lese inn diktet i Python. Her bruker vi den innebygde funksjonen open():
Vi spesifiserer først navnet på filen i funksjonen open(). Det vi egentlig gjør her er å spesifisere en sti93 til filen, altså en beskrivelse av hvor den befinner seg i filsystemet. Her har vi beskrevet en relativ sti94 som forteller oss hvor tekstfilen er relativt til Python-filen vår. Siden begge filene ligger i samme mappe går det fint å bare skrive navnet 'dikt.txt'. Når du kjører koden over er det viktig at du er navigert til samme mappe som der begge filene ligger.
Det andre argumentet 'r' representerer at vi er i lesemodus. Dette angir at vi kun ønsker å lese innholdet i filen. Når du åpner en fil i lesemodus kan du ikke skrive informasjon til filen.
Det er lett å tenke at tekstfil nå inneholder teksten i diktet. Dette stemmer ikke. Variabelen tekstfil representerer grensesnittet mellom programmet vårt og filen. Det er et objekt av typen _io.TextIOWrapper. Dette er et Python-objekt som har metoder vi kan bruke for å lese innholdet i filen. Du trenger ikke bekymre deg mye for dette spesifikke Python-objektet. Vi skal bare lære et par metoder som vi kan bruke på objektet _io.TextIOWrapper.
Den enkleste måten å få tak i alt innholdet i filen er å bruke metoden .read() slik:
Her vil innhold være en god gammeldags streng som inneholder alt i tekstfilen. Når jeg prøver å skrive ut innhold til terminalen får jeg dette:
Vi kan ikkje eige kvarandre
tusen dikt har fortalt oss
at vi ikkje kan eige kvarandre
men vi kan låne kvarandre
og gløyme levere tilbakeDette ser jo nesten riktig ut, bortsett fra at de særnorske bokstavene blir helt tøys. Her kan det være at du får diktet helt perfekt ut. Dette handler om tegnkodingen95 som funksjonen open() gjør når den leser filer. Dette avhenger av hvilken datamaskin du har, med mindre vi spesifiserer dette. Når du leser norsk tekst vil jeg anbefale å sette det valgfrie argumentet encoding i funksjonen open() til å være 'utf-8':
Skriver du ut innhold på nytt vil du få diktet med riktige særnorske bokstaver. Tegnkodingen UTF-8 kan representere nesten alle tegn fra alle verdens skriftspråk, så den er som regel et trygt valg.
Så langt har vi sett på å laste inn hele tekstfilen. Noen ganger ønsker vi derimot å laste inn en linje av gangen for å behandle hver linje separert. Dette kan du gjøre på tre forskjellige måter:
Du kan bruke metoden
.readline()for å hente en enkelt linje.Du kan bruke metoden
.readlines()for å hente alle linjene og lage en liste som inneholder hver enkelt linje som elementer.Du kan skrive en for-løkke der du itererer over grensesnittet (i vårt tilfelle
tekstfil) for å gå gjennom hver enkelt linje.
Hver av de tre måtene å gjøre dette på har sine bruksområder. Hvis du bare ønsker å hente en eller et par linjer i en tekstfil så er .readline() ypperlig. Her bruker vi .readline() til å hente de to første linjene i tekstfilen:
tekstfil = open('dikt.txt', 'r', encoding='utf-8')
første_linje = tekstfil.readline()
andre_linje = tekstfil.readline()Her kan du sjekke ved å skrive ut første_linje og andre_linje at de inneholder første og andre linje i diktet. Som du forstår så gjør hvert kall til metoden .readline() at vi gir ut en linje og deretter hopper videre i filen. Det er grensesnittet tekstfil som holder rede på hvilken linje vi har kommet til i tekstfilen.
Hvis du ønsker å jobbe med hele teksten i tekstfilen, men en linje av gangen, så er både metoden .readlines() eller for-løkker gode valg. Det endelige valget her kommer an på om du trenger å lage en liste, eller om dette ikke er nødvendig. Hvis det er unødvendig så er en for-løkke veldig lettvint slik som her:
tekstfil = open('dikt.txt', 'r', encoding='utf-8')
for linje in tekstfil:
if 'kvarandre' in linje:
print(linje, end='')Kjører du koden over vil du få skrevet ut de tre linjene i diktet som inneholder ordet 'kvarandre'. Vi bruker det valgfrie argumentet end i funksjonen print() for å indikere at vi ikke vil ha linjehopp etter å ha skrevet ut setningen. Grunnen til dette er at da vil vi få to linjehopp siden vi også får et fra linjene i selve tekstfilen. Hadde du skrevet samme funksjonalitet ved å bruke metoden .readlines() ville det sett slik ut:
tekstfil = open('dikt.txt', 'r', encoding='utf-8')
linjer = tekstfil.readlines()
for linje in linjer:
if 'kvarandre' in linje:
print(linje, end='')I dette tilfellet er det enklere å bare direkte skrive en for-løkke over tekstfil siden vi ikke trenger å lagre alle linjene i en liste. Gjør en vurdering om .readline(), .readlines(), eller en for-løkke er best når du skal jobbe med individuelle linjer.
Til slutt kan det være greit å prøve å lese inn en fil som ikke eksisterer:
Kjører du koden over vil du få en FileNotFoundError. Så når du møter på en FileNotFoundError er det typisk at du har stavet filnavnet feil, eller at filen ennå ikke er opprettet.
10.2.2 Skriving til filer
Nå skal vi se hvordan vi skriver informasjon til en fil. For å skrive til en fil bruker vi også funksjonen open(). I motsetning til når vi leser fra en fil så vil filen bli opprettet om den ikke eksisterer fra før av. Vi bruker modusen 'w' når vi skal skrive til filer:
La oss først bare skrive beskjeden 'Hallo verden!' til filen spørsmål.txt. Til dette kan vi bruke metoden .write() slik:
Kjører du koden over vil du lage en tekstfil som heter spørsmål.txt i samme mappe som Python-programmet ditt. Åpner du spørsmål.txt vil du se at filen inneholder teksten 'Hallo verden!'. Ikke veldig overraskende. Det som kanskje er mer overraskende er hva som skjer hvis du kjører koden igjen. Du vil ikke få 'Hallo verden!' repetert to ganger i spørsmål.txt. Når du bruker modusen 'w' så overskriver du hele filen.
La oss nå skrive spørsmålene i quizzen som vi jobbet med i seksjon 9.7 til filen spørsmål.txt. Her har jeg lagt spørsmålene sammen i en liste slik:
quiz_spørsmål = [
'Hvem vant toppserien i fotball for kvinner i 2024?',
'Hvilket land vant VM i fotball for menn i 2022?',
'Hvilket lag vant Champions League for menn i 2023?'
]For å skrive ned de tre spørsmålene i quiz_spørsmål til filen vår må du selv legge til linjehopp for å indikere at vi hopper til en ny linje:
Det kan også være greit for deg å vite at det finnes en .writelines() metode. Her kan du bare sende inn listen quiz_spørsmål så skrives alle strengene til filen slik:
Problemet med dette er klart hvis du ser på innholdet i filen spørsmål.txt etter å ha kjørt koden. Da vil du se at det ikke er noen linjehopp, men at alt har blitt skrevet på samme linje. For både metoden .write() og .writelines() må du selv legge til linjehopp. Når du bruker .writelines() kan du bruke en generatorbeskrivelse som vi lærte om i seksjon 9.6 til å gjøre dette på en elegant måte:
Så langt har vi alltid overskrevet hele filen når vi skriver til en fil. Hvis du bare ønsker å legge til nye linjer med informasjon må du bruke modusen 'a' slik:
tekstfil = open('spørsmål.txt', 'a', encoding='utf-8')
quiz_spørsmål = [
'Hvem vant toppserien i fotball for kvinner i 2024?',
'Hvilket land vant VM i fotball for menn i 2022?',
'Hvilket lag vant Champions League for menn i 2023?'
]
tekstfil.writelines(spørsmål + '\n' for spørsmål in quiz_spørsmål)Hver gang du kjører koden over vil du legge til de tre spørsmålene om igjen og om igjen til filen spørsmål.txt. Både skriving av filer fra bånn med modusen 'w' og det å legge til linjer til filer med modusen 'a' er mye brukt.
10.2.3 Lukking av filer
Vi har brukt funksjonen open() til å lese fra og skrive til filer. Da representerer variabelen som holder grensesnittet (det vi har kalt tekstfil) en kobling mellom Python-programmet vårt og filen. Tenk på dette som en telefonsamtale der vi kan enten få informasjon eller gi informasjon. Vi avslutter en telefonsamtale etter vi er ferdig å gi eller få informasjon. På samme måte må vi lukke grensesnittet til filene når vi er ferdig å jobbe med dem. Vi bruker frasen lukke filen96 selv om det hadde vært mer riktig å snakke om å lukke grensesnittet mellom filen og programmet vårt.
Filene som vi har kommunisert med blir automatisk lukket når Python-programmet vårt er ferdig. Mer kompliserte Python-programmer kan gjøre mye annet før de er ferdige. Derfor er det en god vane å lukke filene vi har åpnet med en gang vi er ferdig med å bruke dem. Dette kan vi gjøre med metoden .close() slik:
tekstfil = open('spørsmål.txt', 'w', encoding='utf-8')
tekstfil.write('Hallo verden!')
tekstfil.close()Uavhengig av om du har bruk modusen 'r', 'w', eller 'a' så gjør metoden .close() at du lukker filen. Ved å lukke filen kan vi ikke lenger skrive til eller lese fra filen. Hva skjer hvis du likevel prøver å skrive til filen?
tekstfil = open('spørsmål.txt', 'w', encoding='utf-8')
tekstfil.write('Hallo verden!')
tekstfil.close()
tekstfil.write('Hallo verden igjen!')Kjører du koden over vil du få en ValueError med feilmeldingen I/O operation on closed file. Forkortelsen I/O står for Input/Output og beskriver lesing og skriving til filen. Så etter at en fil er lukket kan vi verken lese eller skrive til den. Tenk på dette som å prøve å snakke inn i en telefon etter at du har avsluttet samtalen. Vi må da åpne et grensesnitt igjen om vi ønsker å lese fra eller skrive til filen igjen.
Hva er konsekvensene av å glemme å lukke en fil? For det første brukes systemressurser på å holde koblingen åpen. Det er lite effektivt å holde koblinger som ikke brukes åpne. I verste tilfellet kan filer som ikke er lukket riktig føre til at informasjon blir ødelagt.
Moralen er at vi alltid må huske å lukke filer etter vi er ferdige med dem. Heldigvis for oss er det mulig å bruke konteksthåndterere i Python som alltid lukker filer automatisk når vi er ferdige med dem. Dette skal vi nå lære om.
10.3 Konteksthåndterere
Fremfor å bruke funksjonen open() direkte slik vi gjorde i forrige seksjon kan vi bruke den med en konteksthåndterer97. Dette sikrer at filene vi åpner blir lukket etter at vi er ferdige med dem. Her bruker vi nøkkelordet with for å lage en konteksthåndterer:
Vi bruker nøkkelordet as til å binde grensesnittet open() gir til variabelen spørsmål_fil. Etter dette går vi inn i en kodeblokk der vi skriver til filen med metoden .write().
Når kodeblokken i konteksthåndtereren er ferdig så blir filen automatisk lukket. Du trenger derfor ikke bruke metoden .close() selv. Dette gjør konteksthåndterere veldig attraktive siden det da er én ting mindre å huske på.
Konteksthåndterere lar deg også jobbe med 2 eller flere filer samtidig på en elegant måte. Det er en ganske vanlig situasjon at du skal lese fra en fil og skrive til en annen. Da er det beleilig å ha begge filene åpne samtidig slik at du kan lese, behandle, og skrive en linje av gangen. Det er til og med ikke uvanlig at du må lese fra mer enn én fil. La oss gjøre et eksempel på dette nå.
Sett at du har følgende informasjon i en fil år_salg.txt om salg av teddybjørner for et lekeselskap per år:
2021: 57489
2022: 63253
2023: 51374
2024: 73283
2025: 66997I tillegg har du at prisen per teddybjørn har variert per år. Prisen per teddybjørn for hvert år er gitt i en fil år_pris.txt og ser slik ut:
2021: 149
2022: 169
2023: 179
2024: 189
2025: 189Du blir bedt om å lage en lignende tekstfil år_inntekt.txt som beskriver inntekten lekeselskapet fikk fra salg av teddybjørnene. Dette kan du gjøre ved å lese fra to filer, og skrive til en tredje. La oss begynne med å lese inn fra begge filene.
with (
open('år_salg.txt', 'r') as salg_per_år,
open('år_pris.txt', 'r') as pris_per_år
):
salg = salg_per_år.readlines()
pris = pris_per_år.readlines()Vi droppet å spesifisere encoding='utf-8' siden filene bare inneholder tall og symbolet :. Siden det ofte er lite leselig å ha flere open() funksjoner på samme linje har vi brutt dette opp. Som du kan se bruker vi bare et komma i with-utsagnet når vi ønsker å jobbe med flere filer. Her leser vi inn begge filene og henter hver linje i en liste med metoden .readlines().
Vi må nå regne ut inntekt per år. Dette er gitt med antall salg per år multiplisert med pris per år. Til slutt må vi skrive dette til en fil som heter år_inntekt.txt. Koden under fikser dette:
with (
open('år_salg.txt', 'r') as salg_per_år,
open('år_pris.txt', 'r') as pris_per_år,
open('år_inntekt.txt', 'w') as inntekt_per_år
):
# Henter all informasjonen fra filene
salg = salg_per_år.readlines()
pris = pris_per_år.readlines()
# Finner inntekt per år
inntekt = []
for i in range(len(salg)):
inntekt.append(f'{salg[i][:4]}: {int(salg[i][6:]) * int(pris[i][6:])}')
# Skriver resultatet til en fil
inntekt_per_år.writelines(linje + '\n' for linje in inntekt)Som du ser er koden litt mer involvert her. Etter at vi har brukt metoden .readlines() på salg_per_år og pris_per_år handler resten av problemet egentlig om lister med strenger som elementer. Dette løses med løkker, indeksering, og slicing for å hente de riktige tallene ut. Til slutt bruker vi metoden .writelines() med en generatorbeskrivelse for å skrive resultatet til filen år_inntekt.txt.
Merk deg at programmet over er svært sensitivt til hvordan tekstfilene er formatert: Vi finner året det er snakk om ved å hente ut de fire første bokstavene i hver linje i år_salg.txt. Hvis det er et mellomrom på starten av denne linjen så er vi ute å kjøre. Vi må be en stille bønn om at filene er nøyaktig slik vi tror dem er. Hvis filene blir oppdatert hvert år er det godt mulig at et år i fremtiden vil det bli introdusert en feil.
Hva kan vi gjøre for å fikse dette? En mulighet er å bruke strengmetoder som .strip() for å fjerne mellomrom her og der. Dette hjelper, men er litt som å ta et lite plaster på et stort åpent sår. Den bedre løsningen her er å benytte seg av andre filformater enn rene tekstfiler når det kommer til strukturert data. I de neste to seksjonene skal vi gå gjennom hvordan du jobber med CSV-filer og JSON-filer. Dette er filformater som er mye mer egnet for strukturert data.
Til slutt bør du vite at konteksthåndterere kan brukes til mye annet enn å jobbe med filer. Du kan bruke konteksthåndterere til å:
Jobbe med databaser.
Utføre flere ting i parallell med tråder.
Håndtere nettverksforbindelser.
Disse temaene går vi ikke gjennom i denne boken. Likevel er det du har lært et solid grunnlag for å bruke konteksthåndterere i mer avanserte situasjoner.
10.4 CSV
Vi skal nå lære hvordan vi kan lese fra og skrive til CSV-filer. Når det kommer til å lagre strukturerte data er CSV-filer lettere å jobbe med enn ordinære tekstfiler. La oss begynne med hva CSV-filer er. En CSV-fil er en tekstfil som kan se slik ut:
år,salg
2021,57489
2022,63253
2023,51374
2024,73283
2025,Ta teksten over og lim det inn i en fil salg.csv som vi skal jobbe med senere.
Merk først av alt at dette er bare en tekstfil med verdier som er skilt med et komma. Akronymet CSV er en forkortelse for Comma Separated Values. Målet til CSV-filer er å beskrive data inndelt i kolonner og rader. Den første linjen i filen over er en overskrift98 som beskriver de to kolonnene år og salg. Hver linje etter dette representerer en rad med informasjon.
Det er like mange verdier i hver rad som det er overskrifter. Som du ser i raden som inneholder året 2025 så er det ingen verdi som korresponderer til overskriften salg. Da er denne verdien tom. Dette kan for eksempel bety at dataene ennå ikke er tilgjengelige.
Du har sikkert vært borti et regneark i Microsoft Excel der du har rader, kolonner, og verdier i celler. Excel-filer er ganske likt CSV-filer, bare at Excel-filer er en del mer kompliserte siden Microsoft Excel har mye funksjonalitet knyttet til funksjoner, visualiseringer, osv. Du kan tenke på CSV-filer som veldig lettbeinte Excel-filer. Siden CSV-filer er enkle er de mye brukt i alt fra overføring av data over nettet til uttrekk fra databaser.
Før vi begynner med å lese og skrive til CSV-filer vil jeg nevne tre ting som er greit å ha i bakhodet:
En CSV-fil trenger ikke ha overskrifter. Det er fullt mulig å begynne rett på dataen med første rad uten at kolonnene har noen navn. De fleste CSV-filer i praksis vil typisk ha overskrifter siden kolonnenavn gjør det lettere å både jobbe og snakke om innholdet i filene.
En CSV-fil trenger ikke bruke symbolet
,som en separator mellom verdiene. Et annet vanlig valg er symbolet|. Når|brukes som separator kaller noen filene for TSV-filer. Dette er et akronym som på engelsk står for Tab Separated Values. Andre mer late personer, som meg selv, kaller dette også for CSV-filer uten skam.Siden en CSV-fil bare er en tekstfil er det ingenting som hindrer deg i å blande datatyper innenfor en kolonne. Ofte i praksis ønsker du at en kolonne skal kun ha en datatype i seg. I eksempelet over så forventer du at
prisbare har heltall i seg og ikke plutselig strenger. Filen i seg selv har ingen forståelse av datatyper. Når vi derimot skal lese CSV-filer i Python er det fordelaktig at de har konsekvente datatyper i kolonnene.
10.4.1 Lese fra CSV-filer
Siden CSV-filer er tekstfiler er det ingenting i veien for å bruke metoder som .read() til å lese fra og skrive til CSV-filer. Likevel er dette såpass vanlig arbeid at Python har pakken csv i standardbiblioteket som hjelper med dette.
La oss starte med å se hvordan vi kan lese fra CSV-filer. Opprett en Python-fil i samme mappe som der du lagret salg.csv ovenfor og skriv inn følgende kode:
from csv import reader
with open('salg.csv', mode='r', encoding='utf-8') as fil:
grensesnitt = reader(fil)
for rad in grensesnitt:
print(rad)Vi åpner først filen salg.csv med en konteksthåndterer slik vi har lært tidligere. Forskjellen er at vi bruker funksjonen reader() i biblioteket csv for å behandle grensesnittet til CSV-filen representert med variabelen fil. Resultatet som lagres i variabelen grensesnitt kan vi lett behandle med en for-løkke for å skrive ut hver enkelt rad.
Kjører du koden over vil du skrive ut en liste for hver rad i CSV-filen. Den første raden du skriver ut er ['år', 'salg'], den andre er ['2021', '57489'], og så videre.
Ved å bruke funksjonen reader() blir det å jobbe med CSV i bunn og grunn bare å jobbe med lister. Dette er forutsigbart, og noe vi har god trening på fra før av. Sett at du skulle funnet ut av gjennomsnittlig salg i perioden fra 2021 - 2023. Da kunne du skrevet følgende kode:
from csv import reader
gjennomsnitt_salg = 0
relevante_år = ('2021', '2022', '2023')
with open('salg.csv', mode='r', encoding='utf-8') as fil:
grensesnitt = reader(fil)
for rad in grensesnitt:
if rad[0] in relevante_år:
gjennomsnitt_salg += int(rad[1])
gjennomsnitt_salg = round(gjennomsnitt_salg / len(relevante_år))
print(f'Gjennomsnittlig salg mellom 2021 og 2023 var {gjennomsnitt_salg}.')Les koden nøye for å forsikre deg om at du forstår hvert steg. De relevante årene vi skal ta gjennomsnittet over lagrer jeg i en tuppel siden disse verdiene ikke skal endres i resten av programmet.
I hovedlogikken av programmet skriver jeg en for-løkke som går gjennom hver rad og sjekker om den representerer et relevant år. Her bruker jeg nøkkelordet in og dette fungerer helt likt som med lister. Hvis året er relevant legger jeg til salgstallet fra det året til gjennomsnitt_salg. Til slutt deler jeg på antall år vi ser på for å finne gjennomsnittet.
Hvorfor var det behov for å bruke funksjonen int() i linjen
gjennomsnitt_salg += int(rad[1])?
Siden CSV-filer ikke har datatyper blir all data lastet inn som strenger. Dette er tryggest slik at vi ikke mister informasjon. Så vi må bruke int() slik at vi legger sammen heltall og ikke slår sammen strenger.
10.4.2 Skrive til CSV-filer
I tillegg til å lese fra CSV-filer er det nyttig å skrive til CSV-filer. Sett at vi har laget følgende informasjon om en rekke superhelter:
superhelter = [
['navn', 'alder', 'arbeid'],
['Spider-Man', 18, 'student'],
['Iron Man', 45, 'filantrop'],
['Wonder Woman', 1000, 'kriger'],
['Batman', 35, 'detektiv']
]Hvordan kan vi skrive dette til en CSV-fil? Biblioteket csv har i tillegg til funksjonen reader() en funksjon som heter writer(). Så enkelt som dette er det å bruke funksjonen writer() for å skrive til CSV-filer:
from csv import writer
superhelter = [
['navn', 'alder', 'arbeid'],
['Spider-Man', 18, 'student'],
['Iron Man', 45, 'filantrop'],
['Wonder Woman', 1000, 'kriger'],
['Batman', 35, 'detektiv']
]
with open('superhelter.csv', mode='w', newline='', encoding='utf-8') as fil:
grensesnitt = writer(fil)
for rad in superhelter:
grensesnitt.writerow(rad)Du oppretter her en ny CSV-fil med navnet superhelter.csv. Argumentet newline='' sørger for at det ikke legges inn ekstra linjeskift mellom hver linje i superhelter.csv. Ellers bruker du metoden .writerow() for å skrive hver rad i superhelter. Dette er enda et eksempel på at lister som inneholder andre lister er supernyttig!
10.5 JSON
I forrige seksjon så vi at CSV-filer er svært nyttige for å lese og skrive data som passer godt inn i et format med rader og kolonner. Denne typen data kalles ofte for tabulær data99 eller strukturert data100. Ofte er data mer strukturert enn ren tekst, men ikke strukturert nok for klare rader og kolonner. Dette kalles for semistrukturert data101.
Filformatet JSON er ypperlig for å jobbe med semistrukturert data. Den korteste forklaringen på filformatet JSON for oss som er kjent med Python er at JSON ligner mye på ordbøker i Python. Her er en JSON-fil som representerer et par kjente filmer:
[
{
"tittel": "Memento",
"regissør(er)": "Christopher Nolan",
"sjanger(e)": "Thriller",
"rollebesetning": [
{
"skuespiller": "Guy Pearce",
"karakter": "Leonard"
},
{
"skuespiller": "Carrie-Anne Moss",
"karakter": "Natalie"
}
]
},
{
"tittel": "The Matrix",
"regissør(er)": ["Lana Wachowski", "Lilly Wachowski"],
"sjanger(e)": ["Action", "Sci-Fi"],
"rollebesetning": [
{
"skuespiller": "Keanu Reeves",
"karakter": "Neo"
},
{
"skuespiller": "Carrie-Anne Moss",
"karakter": "Trinity"
},
{
"skuespiller": "Laurence Fishburne",
"karakter": "Morpheus"
}
]
}
]Hvis du ser nøye på JSON-filen over kan du gjøre følgende observasjoner:
Under
sjanger(e),regissør(er),rollebesetninger det mulig å ha et variert antall elementer for hver film. Dette gir mening siden filmer har forskjellige antall sjangere, regissører, og skuespillere.I rollebesetninger så er
"skuespiller"og"karakter"flettet sammen i et objekt for å indikere at de hører sammen.
Disse to observasjonene gjør det vanskelig å representere denne dataen som rader og kolonner. Filformatet JSON passer godt til å representere slik semistrukturert data.
Selv om JSON-filer har mange likhetstrekk med ordbøker i Python er det noen forskjeller. I JSON-filer kan du bruke verdier som strenger, heltall, sannhetsverdiene true og false, osv. Merk at sannhetsverdiene true og false i JSON-filer er skrevet med små forbokstaver i kontrast med True og False i Python. Det er ikke mulig å bruke tupler eller mengder i JSON-filer, så du har færre datatyper til rådighet. Du finner likevel analogier til lister og ordbøker i JSON, som vist i filmeksempelet over.
Akronymet JSON er en forkortelse på engelsk for Javascript Object Notation og har sin opprinnelse i programmeringsspråket JavaScript. I dag brukes filtypen JSON til overføring av semistrukturert data mellom mange forskjellige systemer. Du skal nå lære å lese fra og skrive til JSON-filer ved å bruke Python.
10.5.1 Lese fra JSON-filer
La oss først prøve å lese inn JSON-filer ved å bruke det vi har lært tidligere. Ta teksten fra JSON-filen ovenfor og lim den inn i en fil som du kaller filmer.json. Opprett så en Python-fil i samme mappe. Vi lærte i seksjon 10.3 at følgende kode leser inn filen filmer.json linje for linje:
Kjører du koden over får du skrevet ut en lang liste der hvert element er en linje i filen filmer.json. Dette er ikke så nyttig. Vi ikke er interessert i formateringen til dokumentet i form av mellomrom eller valg av hvor vi legger inn nye linjehopp. Vi er interessert i informasjonen og relasjonene mellom bitene med informasjon. En enkel oppgave som å skrive ut titlene på de to filmene er nå vrient.
Heldigvis har Python innebygd funksjonalitet som gjør livet vårt mye enklere. Vi skal bruke pakken json i standardbiblioteket til å både lese fra og skrive til JSON-filer. Vi kan fremfor å bruke metoden .readlines() bruke funksjonen json.load() slik:
import json
with open('filmer.json', mode='r', encoding='utf-8') as fil:
data = json.load(fil)
print(data)Når du kjører denne koden vil du igjen få ut en liste. Informasjonen i listen vil være brutt opp i databiter fremfor å være basert på linjehopp. Listen data har to elementer som representerer de forskjellige filmene. Hvert element er en ordbok som vi kan hente informasjon ut av. Her kan du se at vi lett kan hente de to titlene:
Objektene vi jobber med her er ikke nye datatyper. Dette er bare lister og ordbøker inni hverandre. For å skrive ut skuespillerne til de den første filmen kan vi skrive følgende kode:
memento = data[0]
print(f'Film 1: {memento["tittel"]}')
print('Skuespillere: ')
rollebesetning = memento['rollebesetning']
for rolle in rollebesetning:
print(rolle['skuespiller'])Først lagrer vi den riktige filmen i variabelen memento. Dette er en ordbok som blant annet har nøklene 'tittel' og 'rollebesetning'. For rollebesetningen til filmen så gir variabelen rollebesetning oss en liste som vi kan jobbe videre med. Vi bruker til slutt en for-løkke for å skrive ut de enkelte skuespillerne. Som du merker så handler lesing av JSON-filer i stor grad om å jobbe med lister og ordbøker etter at du har brukt funksjonen json.load().
10.5.2 Skrive til JSON-filer
Vi kan også skrive til JSON-filer. Her bruker vi funksjonen json.dumps() for å skrive til JSON-formatet. Funksjonen json.dumps() returnerer en streng, så vi kan foreløpig bare skrive denne til terminalen for å teste litt:
Kjører du koden over vil du se følgende streng bli skrevet ut til terminalen:
[1, {"hei": "hade"}, [true, false, null]]
Dette eksempelet illustrerer mange av de viktigste prinsippene ved skriving til JSON-filer. Du kan se at lister og ordbøker blir bevart, mens tupler blir omgjort til lister. Verdiene True og False blir omgjort til true og false siden JSON skriver sannhetsverdiene med små forbokstaver. Verdien None blir omgjort til null siden dette er JSON sin konvensjon på en manglende verdi.
For å skrive dette til en fil framfor til terminalen bruker vi en standard konteksthåndterer:
import json
json_tekst = json.dumps([1, {'hei': 'hade'}, (True, False, None)])
with open('test.json', 'w') as fil:
fil.write(json_tekst)Kjører du koden over vil du opprette en ny JSON-fil med navnet test.json i samme mappe som Python-filen din.
Det er utrolig mye du kan bruke JSON-filer til! Et eksempel er å lagre data fra en kort spørreundersøkelse. Her har du en veldig enkel versjon av dette ved å bruke funksjonene input() og json.dumps():
import json
svarinformasjon = {}
navn = input('Hva er navnet ditt? ')
svarinformasjon['navn'] = navn
alder = int(input('Hvor gammel er du? '))
svarinformasjon['alder'] = alder
favorittmat = input('Hva er din favorittmat? ')
svarinformasjon['favorittmat'] = favorittmat
with open(f'{navn}.json', 'w') as fil:
fil.write(json.dumps(svarinformasjon))Du er sikkert vant med at spørreskjemaer er litt mer lekre rent visuelt enn et terminalvindu. Likevel kan du nå skrive all logikken for et spørreskjema og lagre informasjon i en JSON-fil. Selv de lekreste spørreskjemaene du finner på moderne nettsider må inkludere kode som lagrer informasjonen, ellers går den bare tapt!
10.6 Binærobjekter
Selv om både CSV-filer og JSON-filer føles litt forskjellige ut, er de begge tekstfiler. Så langt i kapittelet har vi bare sett på tekstfiler. Hva med andre typer filer? I tillegg til tekstfiler har vi filtyper som for eksempel bilder (.jpg), videoer (.mp4), lydfiler (.mp3), programmer (.exe), og komprimerte filer (.zip).
Filer som ikke er tekstfiler kaller vi for binærfiler102. Innholdet i binærfiler er sekvenser med enheter bestående av 8 bits (altså en byte). Slike filer behandles av andre typer programmer enn tekstprogrammer. Du bruker sannsynligvis egne programmer for å åpne bilder, videoer, og lydfiler. Prøver du å åpne et bilde i et tekstprogram som Notepad eller TextEdit så får du bare opp kryptiske symboler.
Vi skal se på hvordan vi kan lese og skrive binærfiler med Python. Ved å gå gjennom dette kommer vi til å møte på en datatype i Python som heter bytes103. Dette er, som du sikkert har forstått av navnet, en datatype som er egnet til å jobbe med binærfiler.
10.6.1 Lese fra binærobjekter
La oss bruke et bilde som eksempel på en binærfil. Jeg velger å bruke det følgende bildet som heter pingvin.jpg av en glad og fornøyd pingvin i papir:

Du kan selv bare velge et hvilket som helst bilde du ønsker å jobbe med. Large bildet som en JPG-fil i samme mappe som Python-koden din. Opprett en Python-fil og skriv følgende kode som vi har sett før:
Kjører du koden over vil du få en UnicodeDecodeError. Feilmeldingen du får vil fortelle deg at det ikke er mulig å dekode bytene i filen til karakterer. Det er altså ikke mulig å lese en binærfil på samme måte som en vanlig tekstfil.
Måten å fikse dette på er likevel enkel. I tillegg til modusen 'r' for lesing av tekstfiler så støtter funksjonen open() også modusen 'rb' for å lese binærfiler:
Denne koden kjører helt fint. Nå må vi bare forstå hva innhold representerer. Vi kan ikke akkurat forvente at innhold er en streng siden innholdet i pingvin.jpg ikke er tekst. Hva er innhold? Kjør koden under for å undersøke dette litt nærmere:
with open('pingvin.jpg', 'rb') as file:
innhold = file.read()
print(type(innhold))
print(innhold[0], innhold[1], innhold[2])Du vil her få skrevet ut at datatypen til innhold er bytes. Datatypen bytes er en sekvens som holder byte-verdier. På samme måte som med lister og tupler så kan vi bruke indeksering til å hente ut elementene. Når jeg skriver dette ut i terminalen, får jeg 255 216 255. Har du brukt et annet bilde enn meg vil du få ut andre verdier her.
Husk at en byte er 8 bit, altså 8 valg av nullere og enere. Dette gir oss \(2^8 = 256\) mulige kombinasjoner med en byte. Så en byte kan representeres som et tall mellom 0 og 255. Dette er innholdet vi har skrevet ut ovenfor.
I Python er datatypen bytes ikke mulig å endre. Så det er mange likheter mellom datatypen bytes og tupler der du kun legger inn heltallsverdier mellom 0 og 255. I Python er bytes veldig effektivt for å representere binærdata.
10.6.2 Skrive til binærobjekter
Akkurat som du kan bruke argumentet 'rb' for å lese binærfiler kan du bruke 'wb' for å skrive til binærfiler. Her ser du hvordan vi kan bruke Python til å kopiere et bilde:
original_sti = 'pingvin.jpg'
kopi_sti = 'ny_pingvin.jpg'
with open(original_sti, 'rb') as original, open(kopi_sti, 'wb') as kopi:
innhold = original.read()
kopi.write(innhold)Som du ser jobber konteksthåndtereren med begge filene samtidig. Vi leser innholdet fra originalfilen og skriver dette til en ny fil. Slik sett er det lite nytt med å skrive til binærfiler.
Det frister kanskje å manipulere bytes slik at du kan endre bilder, musikk, eller video? For dette brukes vanligvis spesialiserte eksterne pakker. Du kan søke opp den eksterne pakken Pillow hvis du ønsker å se hvordan du kan manipulere bilder i Python. Tenk deg at du lager en nettbasert applikasjon der brukere skal laste opp profilbilder. Da må du kanskje skalere størrelsen på profilbildene slik at det ser likt ut. For slike formål er biblioteket Pillow supert.
Et annet vanlig bruksområde når det kommer til binærfiler er filkomprimering104. Du har kanskje brukt et klikkbasert verktøy til å lage en zip-fil av en mappe. Det finnes mange forskjellige algoritmer for å komprimere filer. Dersom vi ønsker å komprimere en enkel fil fremfor en mappe kan vi bruke det innebygde biblioteket gzip i Python. Her kan du se et lite program som komprimerer filen filmer.json vi jobbet med i seksjon 10.5 til en fil med filtype .gz:
import gzip
original_fil = 'filmer.json'
komprimert_fil = 'filmer.json.gz'
with (
open(original_fil, 'rb') as original,
gzip.open(komprimert_fil, 'wb') as komprimert
):
komprimert.write(original.read())Her bruker vi funksjonen gzip.open() til å lage en ny komprimert fil av typen .gz. Oppførselen til gzip.open() er veldig lik den innebygde open() funksjonen. Som du kan se inne i konteksthåndtereren så leser vi først informasjonen i JSON-filen med metoden .read() på grensesnittet original. Deretter skriver dette til den komprimerte filen med metoden .write() på grensesnittet komprimert.
Du lurer kanskje på hvorfor vi bruker modusen 'rb' når vi leser tekstfilen filmer.json? Siden vi ønsker å skrive bytes til filen filmer.json.gz via grensesnittet komprimert så er det enklere å lese tekstfilen som en binærfil og få informasjonen som bytes. Vanligvis ønsker vi å behandle tekstfiler som tekst, men akkurat i dette tilfellet er det enklest å tenke på filen som en sekvens med bytes.
Når jeg sammenligner størrelsene så er den originale filen filmer.json 847 bytes. Den komprimerte filen filmer.json.gz er bare 313 bytes. Så her sparer vi 63 % av lagringsplassen! I vårt eksempel er det bare snakk om under en kilobyte, så det har jo fint lite å si i praksis. Men med større datamengder kan dette være veldig besparende. Du kan ta en titt på bibliotekene gzip, zipfile, og bz2 i standardbiblioteket dersom du er mer interessert i komprimering av mapper og filer.
10.7 Prosjekt - Analysere hyppigheten på bokstaver i Frankenstein
I dette prosjektet skal vi lage et program som analyserer hvilke bokstaver det er flest av i den klassiske boken Frankenstein av Mary Wollstonecraft Shelley. Vi skal rett og slett telle opp hvor mange ganger Mary har brukt bokstaven 'a', bokstaven 'b', og så videre. Dette hadde vært veldig tidkrevende å gjøre uten programmering. Vi skal se at dette ikke er så vanskelig som det høres ut nå som vi kan lese fra filer.
10.7.1 Oppgaven
Siden Frankenstein er i det offentlige domenet har jeg hentet boken som en tekstfil fra prosjekt Gutenberg. Du kan selv enkelt finne Frankenstein i tekstformat ved å søke opp frankenstein txt file i din prefererte søkemotor og deretter kopiere teksten inn i en tekstfil. Jeg har gjort nettopp dette og kalt filen for frankenstein.txt. Som du kan se er dette en ganske lang tekstfil:
Målet er som sagt å lese inn tekstfilen og deretter se hvor mange ganger Mary Wollstonecraft Shelley bruker de forskjellige bokstavene i teksten. Vi ønsker også å rapportere prosentvis fordeling av de forskjellige bokstavene relativt til lengden på boken. Til slutt hadde det vært fint å plotte dette som et stolpediagram for å lett kunne visualisere resultatet. La oss sette i gang!
10.7.2 Lese inn tekstfilen
Lag deg en Python-fil som heter telle_ord.py i samme mappe du lagret tekstfilen frankenstein.txt. La oss starte med å lese inn tekstfilen. Dette er relativt rett frem og noe vi har gjort mange ganger i løpet av kapittelet. Vi bruker en konteksthåndterer og skriver følgende:
with open('frankenstein.txt', 'r', encoding='utf-8') as fil:
innhold = fil.read()
print(innhold[:100])Her har jeg brukt nøkkelargumentet encoding='utf-8' siden bøker ofte har spesialtegn, og da er UTF-8 en grei standard å bruke. Vi bruker slicing for å skrive ut de første 100 bokstavene i strengen innhold. Strengen innhold er en temmelig lang streng. Hvor lang? La oss sjekke dette ved å bruke funksjonen len():
with open('frankenstein.txt', 'r', encoding='utf-8') as fil:
innhold = fil.read().lower()
antall_tegn = len(innhold)
print(f'Det er {antall_tegn} antall tegn i boken Frankenstein.')Når vi teller bokstaver, ønsker vi ikke å skille mellom store og små bokstaver. Derfor bruker vi strengmetoden .lower() for å gjøre alle tegnene om til små bokstaver.
Kjører du dette vil du se at det er over 400 000 tegn i Frankenstein. Det nøyaktige antallet tegn du får bør tas med en klype salt. Husk at mellomrom mellom ord eller linjehopp også teller som tegn her, så det nøyaktige antallet vil variere litt avhengig av hvilken versjon av boken du velger og hvordan du har kopiert det inn i en tekstfil. Men at det er over 400 000 tegn kan man nok trygt si.
10.7.3 Bruke ordbøker til å telle
La oss nå telle hvor mange ganger hver bokstav dukker opp i teksten som er lagret i variabelen innhold. En måte å gjøre dette på er å bruke en ordbok der hver nøkkel er bokstavene i alfabetet. Her ser du en liten versjon av dette med de tre første bokstavene i alfabetet:
Vi setter verdiene foreløpig til 0 før vi begynner å telle. Fremfor å føre inn alle tegnene i det engelske alfabetet slik kan vi være litt lur og gjøre dette:
bokstaver = 'abcdefghijklmnopqrstuvwxyz'
fordeling = {}
for bokstav in bokstaver:
fordeling[bokstav] = 0Det var ikke så dumt, eller hva? Vi har nå laget en ordbok med 26 nøkler som tilsvarer de forskjellige bokstavene i det engelske alfabetet. Hvis du skal være sikker på at vi har skrevet alle bokstavene i riktig rekkefølge må du lese temmelig nøye gjennom verdien til bokstaver. Det du heller kan gjøre er å bruke standardbiblioteket string som har en del nyttige strenger som er allerede laget. Strengen vi lagret i variabelen bokstaver finner du nemlig der:
from string import ascii_lowercase as bokstaver
fordeling = {}
for bokstav in bokstaver:
fordeling[bokstav] = 0Som du kan se så heter strengen ascii_lowercase i biblioteket string. Jeg omdøper den her til bokstaver med nøkkelordet as siden jeg synes dette er litt mer forståelig for de fleste.
Da er ordboken vår klar. Vi skriver nå bare en enkel for-løkke som går gjennom hvert tegn i strengen innhold og sjekker om det er noen av bokstavene i det engelske alfabetet. Når dette er tilfellet, oppdaterer vi den korresponderende verdien i fordeling. Prøv selv på dette før du leser den fulle koden under:
from string import ascii_lowercase as bokstaver
# Leser inn hele boken som en streng
with open('frankenstein.txt', 'r', encoding='utf-8') as fil:
innhold = fil.read().lower()
antall_tegn = len(innhold)
# Setter opp en ordbok for å telle tegnene i boken
fordeling = {}
for bokstav in bokstaver:
fordeling[bokstav] = 0
# Teller opp tegnene i boken
for tegn in innhold:
if tegn in fordeling:
fordeling[tegn] += 1
print(fordeling)Kjører du koden over vil du se at vi nå har telt opp hvor mange ganger hver bokstav brukes i boken. Som et eksempel er bokstaven 'a' brukt over 25 000 ganger, mens bokstaven 'x' bare er brukt rundt 650 ganger. Dette er ikke overraskende siden noen bokstaver blir oftere brukt en andre. Ta en titt på hvor mange ganger de forskjellige bokstavene har blitt brukt før vi går videre.
10.7.4 Standardbiblioteket collections
Måten vi har telt opp hyppigheten til hver bokstav er helt gyldig. Dette er derimot en såpass vanlig situasjon at Python har en pakke i standardbiblioteket som håndterer dette. I pakken collections så er det et Counter klasse som gjør nettopp dette på en enkel måte.
Du kan rett og slett sende strengen innhold inn i klassen Counter slik:
from string import ascii_lowercase as bokstaver
from collections import Counter
# Leser inn hele boken som en streng
with open('frankenstein.txt', 'r', encoding='utf-8') as fil:
innhold = fil.read().lower()
antall_tegn = len(innhold)
# Teller opp tegnene i boken
fordeling = Counter(innhold)
for bokstav in bokstaver:
print(f'{bokstav}: {fordeling[bokstav]}')Merk at vi importerer Counter fra standardbiblioteket collections. Etter at vi har lastet inn innholdet fra Frankenstein oppretter vi et Counter objekt som vi kaller fordeling ved å passere inn innhold i klassen Counter. Nå kan vi bare gå gjennom hver bokstav i bokstaver og se hvor mange ganger bokstaven forekommer i Frankenstein. Merk at vi bruker notasjonen fordeling[bokstav]. På mange måter er Counter bare en ordbok med spesiell funksjonalitet for opptelling som gjør koden vår enklere og kortere.
10.7.5 Prosenter og plotting
La oss nå regne ut hvor stor prosent av teksten hver bokstav i det engelske alfabetet bruker i Frankenstein. Dette er enkelt siden vi har både lengden på hele teksten og hyppigheten til hver enkelt bokstav. Jeg velger å samle opp prosentene i en liste siden det engelske alfabetet har en naturlig rekkefølge. Dette vil også gjøre det enklere når vi lager stolpediagrammet etterpå:
Her bruker jeg en listebeskrivelse til å bygge prosentvis hyppighet for hver bokstav. Merk at dersom du summerer opp verdiene i prosenter med funksjonen sum() så vil du få noe ganske langt fra 100. Dette er fordi vi har ekskludert andre tegn enn vanlige bokstaver. Så tegn som mellomrom, linjehopp, eller tall blir ikke talt opp selv om de er en del av den totale mengden tegn gitt i antall_tegn.
La oss nå tegne prosentene i et stolpediagram. Her kunne vi brukt matplotlib slik vi gjorde i seksjon 8.5. Jeg velger heller, for variasjonens skyld, å bruke det eksterne biblioteket seaborn. Dette er et bibliotek som bygger på matplotlib der det er enkelt å lage en drøss med forskjellige figurer. Start med å kjøre kommandoen pip install seaborn i terminalen for å laste ned seaborn.
I biblioteket seaborn har vi en funksjon som heter barplot(). Du kan sjekke ut dokumentasjonen til barplot() ved å følge lenken her:
https://seaborn.pydata.org/generated/seaborn.barplot.html
Funksjonen barplot() hjelper oss med å lage stolpediagrammer. La oss gjøre et forsøk på dette:
Kjører du koden nå vil den krasje, og du vil få en kryptisk KeyboardInterrupt. Dette illustrerer noe som kan være en utfordring med eksterne biblioteker: De har ofte dårligere feilmeldinger som kan være vanskelig å forstå. Her er det ett eller annet som går galt når vi kaller barplot(), men litt uklart nøyaktig hva.
Problemet her er at bokstaver ikke er en liste, men en streng. Vi må konvertere dette til en liste der hvert element er hver enkelt bokstav. Dette kan vi gjøre med funksjonen list() og koden blir slik:
Kjører du koden nå får du ingen feilmelding. Men figuren vil heller ikke dukke opp automatisk for de fleste her. Du kan bruke matplotlib til å fremvise figurer i seaborn:
from seaborn import barplot
import matplotlib.pyplot as plt
barplot(x=list(bokstaver), y=prosenter)
plt.show()Hvis du ikke har gått gjennom kapittel 8 har du muligens ikke matplotlib installert fra før av. Da er det bare å skrive kommandoen pip install matplotlib i terminalen for å fikse dette. Kjører du koden nå vil du få opp en figur som ser noenlunde slik ut:
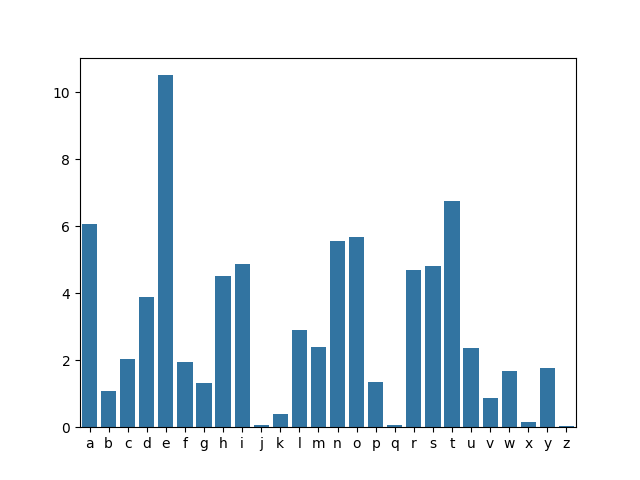
Suksess! Her kan vi se at bokstaven 'e' er den vanligste, etterfulgt av bokstavene 't' og 'a'. Noen bokstaver som 'j', 'q', 'x', og 'z' blir ganske sjelden brukt på engelsk. Denne fordelingen er lignende på norsk, bortsett fra at bokstaven 'j' er mer brukt på norsk enn på engelsk.
Dette bilde hadde jo vært hyggelig å sende til familie og kjentfolk. For å gjøre dette må vi lagre det som en fil først. Her er det fristende å skrive sin egen kode med en konteksthåndterer. Men heldigvis er dette så vanlig at matplotlib lett fikser dette. Du kan bruke funksjonen plt.savefig() for dette slik:
Du vil nå finne et PNG-bilde med navnet stolpediagram.png i mappen du kjører koden i. Så enkelt var det! Her kan du se hele koden vi har skrevet:
from string import ascii_lowercase as bokstaver
from collections import Counter
from seaborn import barplot
import matplotlib.pyplot as plt
# Leser inn hele boken som en streng
with open('frankenstein.txt', 'r', encoding='utf-8') as fil:
innhold = fil.read().lower()
antall_tegn = len(innhold)
# Teller opp prosentvis deltakelse av hver bokstav
fordeling = Counter(innhold)
for bokstav in bokstaver:
print(f'{bokstav}: {fordeling[bokstav]}')
prosenter = [fordeling[bokstav]/antall_tegn * 100 for bokstav in bokstaver]
# Lager et stolpediagram og lagrer dette
barplot(x=list(bokstaver), y=prosenter)
plt.savefig('stolpediagram.png', format='png')10.7.6 Kryptografi og andre verdenskrig
Det å telle enkelte bokstaver i en tekst virker kanskje litt tøysete. Har dette egentlig noen verdi? Ja, faktisk så har det en kul applikasjon. I kryptografi har det tradisjonelt vært vanlig å bytte om bokstaver for å lage hemmelige beskjeder. Sett at jeg lager regelen om at 'h' byttes med 'y', 'e' byttes med 'k', og 'i' byttes med 'a'. Da blir beskjeden min 'hei' gjort om til 'yka'. Denne beskjeden kan nå sendes over en usikker kanal som for eksempel Internett. Da vil ingen vite hva dette betyr annet en min sammensvorne som også har blitt fortalt regelen for hvordan bokstaver skal byttes.
Hvordan kan en som finner den krypterte beskjeden knekke koden? Dersom en stor nok mengde tekst har blitt funnet kan hun bruke hyppighetsanalyse105. Dette innebærer nettopp å telle den prosentvise hyppigheten til tegnene i den krypterte beskjeden slik vi har gjort det. Hvis det er størst mengde av bokstaven 'x' i den krypterte beskjeden, er jo dette en indikasjon på at kanskje 'e' har blitt byttet om til 'x'. Jo mer tekst du har, jo mer sikker kan du være på slik antagelser. Dette kan du bruke til å knekke koden hvis du har funnet en stor nok mengde tekst!
Hyppighetsanalyse ble brukt som en sentral del under andre verdenskrig av de allierte til å knekke Tyskland sine hemmelige beskjeder. Dette var komplisert arbeid som bygget på tidligere oppdagelser til polske matematikere. Evnen til å knekke Tyskland sine hemmelige beskjeder lot de allierte få et strategisk overtak. Så telling av bokstaver i tekst er ikke så bortkastet likevel.
10.8 Oppgaver
Oppgave 1
Du har fått en fil innbyggerdata.txt som inneholder navn og alder på personer som har svart på en spørreundersøkelse. Hver linje i filen har på formen:
Ida,17
Jonas,34
Fatima,70
Mikkel,15
Kari,45Hva gjør følgende kode? Beskriv hvert steg!
with (
open('innbyggerdata.txt', 'r', encoding='utf-8') as datafil,
open('mindreårige.txt', 'w', encoding='utf-8') as mindreårige_fil,
open('voksne.txt', 'w', encoding='utf-8') as voksne_fil
):
for linje in datafil:
navn, alder = linje.strip().split(',')
alder = int(alder)
if alder < 18:
mindreårige_fil.write(f'{navn} er {alder} år og mindreårig.\n')
else:
voksne_fil.write(f'{navn} er {alder} år og regnes som voksen.\n')Oppgave 2
I denne oppgaven skal du lese inn data fra en CSV-fil om forskjellige racerførere og gjøre noen enkle analyser. Kopier følgende data under i en fil med navnet runder.csv.
navn,alder,bilmerke,runder_fullført
Emma Foss,28,Ferrari,72
Jonas Berg,34,Mercedes,65
Sofie Nilsen,26,Red Bull,70
Marius Holm,31,Ferrari,61
Ida Aas,29,McLaren,74
Tobias Lie,36,Mercedes,69
Nora Strand,30,Red Bull,68Du skal skrive et Python-program som gjør følgende:
Les inn
runder.csvog finn ut hvilken fører som har fullført flest runder.Beregn gjennomsnittsalderen til racerførerne.
Skriv til en ny CSV-fil
drivstoff.csvsom har de to kolonnenenavnogdrivstoff_liter. Hver linje skal inneholde navnet til racerføreren og estimert drivstofforbruk. Du kan anta at én runde bruker 3.5 liter drivstoff.
Oppgave 3
Skriv et program som spør brukeren hva deres to favorittspill er. Du skal spørre om følgende informasjon:
tittel: Tittel på spillet (streng)plattform: Plattform (f.eks. PC, Switch, PS5) (streng)spilletid_timer: Estimert spilletid i timer (heltall)sjanger: Hvilken sjanger er spillet? (liste med strenger)
Samle informasjonen fra brukeren i en liste med ordbøker, der hver ordbok representerer ett spill. Du kan la brukeren skrive inn flere sjangre som en komma-separert liste, og bruke metoden .split(',') for å gjøre det om til en Python-liste.
Skriv all informasjonen til en fil som heter favorittspill.json. Filen du ender opp med skal ha samme form som dette:
[
{
"tittel": "Hades",
"plattform": "PC",
"spilletid_timer": 55,
"sjanger": ["Action", "Roguelike"]
},
{
"tittel": "Overcooked 2",
"plattform": "Switch",
"spilletid_timer": 40,
"sjanger": ["Party", "Simulation"]
}
]Oppgave 4
Tallet \(\pi = 3.141592...\) er et såkalt irrasjonalt tall, som betyr at desimalene aldri stopper og aldri gjentar seg. Mange har lurt på hvor tilfeldig desimalene i \(\pi\) egentlig er. Er noen sifre mer vanlige enn andre?
I denne oppgaven skal du utforske de første 250 desimalsifrene i \(\pi\). Oppgaven er å lage et stolpediagram ved hjelp av matplotlib som viser fordelingen av sifre fra 0 til 9. Nedenfor finner du de første 250 desimalsifrene i \(\pi\), som du kan kopiere inn i en tekstfil:
3.141592653589793238462643383279502884197169399375105820974944592307816406286
20899862803482534211706798214808651328230664709384460955058223172535940812848
11174502841027019385211055596446229489549303819644288109756659334461284756482
337867831652712019091Oppgave 5 (Utfordrende)
Du har forsøkt å sende en stor videofil til en venn på e-post, men filen er for stor til å bli sendt i én omgang. Heldigvis kan både du og vennen din litt Python!
Planen deres er:
Dele opp filen i 10 mindre filer, basert på innholdet i bytes.
Sende de små filene enkeltvis.
Sette dem sammen igjen i riktig rekkefølge hos vennen din.
Din oppgave er å først lage et program som leser inn en binærfil og deretter deler opp og skriver innholdet til 10 mindre filer. Deretter skal du skrive et program som leser inn de 10 mindre filene og setter dem sammen igjen til én stor bytes-sekvens som du skal skrive til en ny fil. På denne måten kan dere komme dere forbi størrelsesbegrensningen.
Tips: Du kan bruke heltallsdivisjon og slicing på datatypen bytes for å dele opp filen i mindre biter.